Is it agentic enough? Benchmarking open models on your own tooling
Researchers published new findings on Is it agentic enough? Benchmarking open models on your own tooling: is it agentic enough? Benchmarking open models on your own tooling
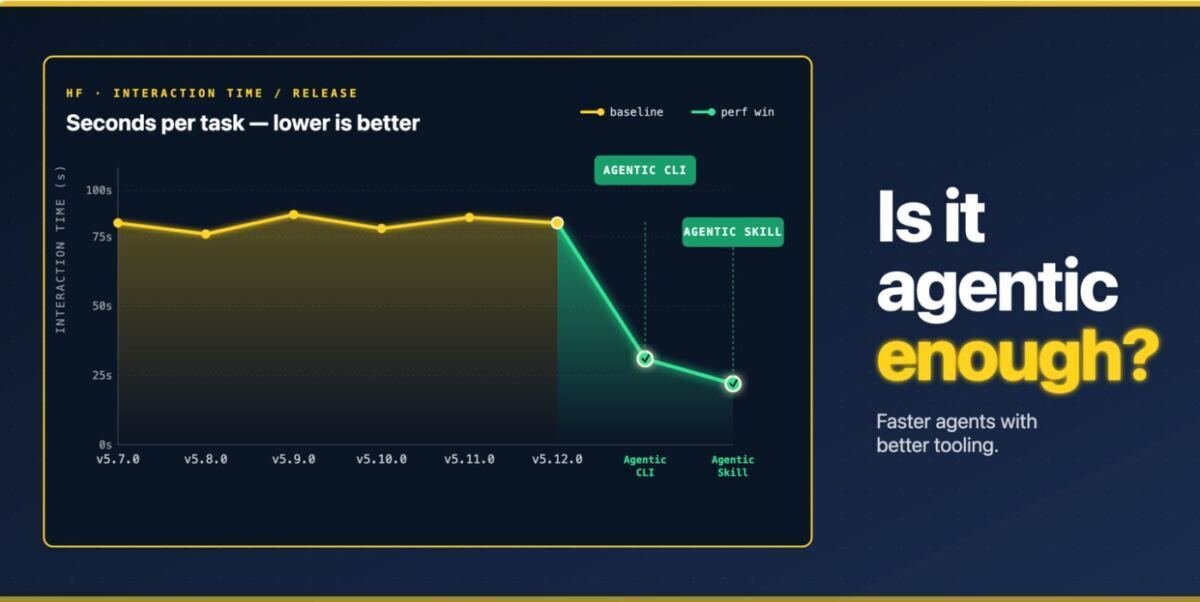
This introduces a new concept in library development: the code should not only be correct and fast, but should be designed so that an agent can drive it effectively. A clunky API or stale docs annoy us developers, but it now also sends the agent down a longer, more expensive path. Most benchmarks just look at the final answer. We wanted the whole process instead: not just whether the agent got it right, but how much work it took to get there, and how that shifts across models, library revisions, and tasks. We measured exactly that, using transformers as our case study. Here, we will introduce a tool specific benchmark focusing on how the answer was found, and provide a simple implementation of one such harness, running entirely on open models driven by the pi coding agent, with the full sweep of models × revisions × tasks fanned out across Hugging Face Jobs so every run sees identical hardware. We’re strong believers in the following two software principles: This remains the same within the realm of agentic-optimized tooling, and, for once, the two are directly tied to each other. You want your tool to exist for an agent: it needs to be discoverable. The API needs to be clear and the docs need to be extensive. They need to be structured in a way that the agent has rapid access to the useful files and examples. If you want your tool to work for an agent, then you should test it for agentic-use. Testing software for agentic-use We’ll use transformers as an example throughout this blogpost: agents using it to solve ML tasks (classifying text, captioning images, transcribing audio), not contributing code to it; though the harness was designed to work with any tool that can be operated from the command line.



